
AppCrawler自动遍历工具 1.7.0 版本
新版本已经发布请关注 https://testerhome.com/topics/node83. 暂时结贴.
关于AppCrawler的先前介绍
相关文章: https://testerhome.com/search?q=appCrawler
腾讯安全部门也有使用 https://security.tencent.com/index.php/blog/msg/105
开源仓库地址: https://github.com/seveniruby/AppCrawler 最新版本在1.7.0分支
获取方式
百度网盘: https://pan.baidu.com/s/1bpmR3eJ
在线帮助文档: https://seveniruby.gitbooks.io/appcrawler/content/
AppCrawler交流专区: https://testerhome.com/topics/node83 论坛帖我会有问必答
问答QQ群:177933995 能获取最新的内测版本参与交流,
自动遍历的价值
- 回归测试.遍历基本的界面, 了解主要界面的可用性. 比如兼容性, 基本功能
- 利用遍历获取app的加载时间和性能数据, 需要借助其他的性能数据抓取工具,比如OneApm, NewRelic
- 利用遍历验证app的内存泄漏以及稳定性等功能, 需要借助LeakCanary和MLeaksFinder
- UI diff 验证新老版本的功能差异. 并识别细节的问题
- 抓取接口请求 辅助验证一些模块基本接口, 并辅助分析接口调用流程. 为接口测试做准备
1.7.0版本改进
增加点击前后的截图
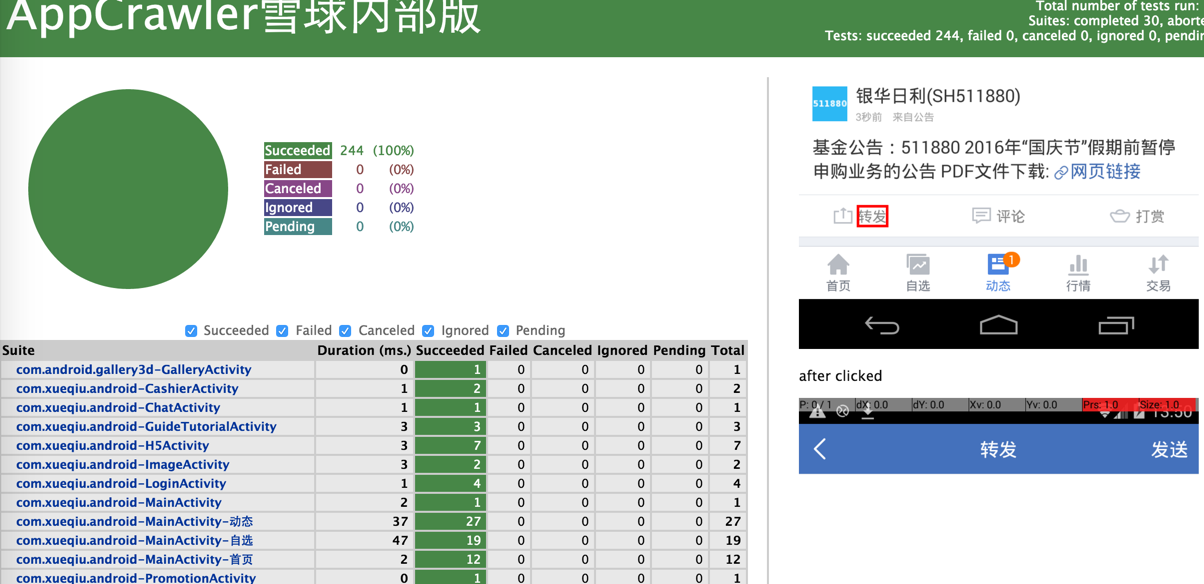

action字段支持scala编程语句
配置文件已经转向YAML格式. 并提供了注释
beforeElementAction afterElementAction triggerActions中的action都可以执行scala语句. 方便自定义.
---
triggerActions:
- action: "click"
xpath: "//*[@resource-id='com.xueqiu.android:id/button_login']"
times: 1
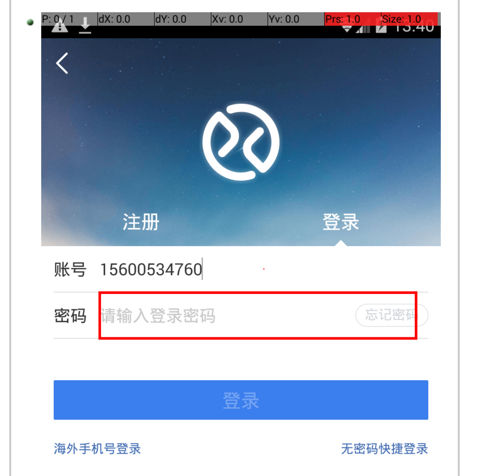
- action: "1560053xxxx"
xpath: "//*[@resource-id='com.xueqiu.android:id/login_account']"
times: 1
- action: "click"
xpath: "//*[@resource-id='com.xueqiu.android:id/login_account']"
times: 1
- action: "xxxxxx"
xpath: "//*[@resource-id='com.xueqiu.android:id/login_password']"
times: 1
#特定控件多遍历几次
tagLimit:
- xpath: //*[../*[@selected='true']]
count: 12
- xpath: //*[../../*/*[@selected='true']]
count: 12
startupActions:
- swipe("left")
- swipe("left")
- swipe("down")
- println(driver)
beforeElementAction:
- Thread.sleep(3000)
- println(driver.getPageSource())
afterElementAction:
- println(driver)
- println(driver.getPageSource)
- Thread.sleep(3000)
对比报告
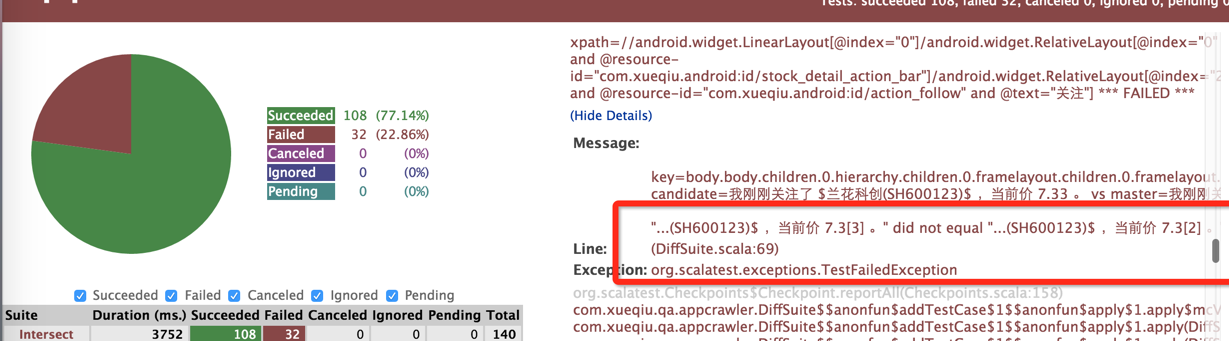
一个简陋粗糙的diff报告. 这个只是初版. 具体什么范围需要对比需要工具使用者自己判断和控制
下个版本也会重点扩展这个功能. 增加字段的黑白名单和自定义规则控制.
如何遍历app并定义每个控件的命名是一门艺术. 请先看文档.
appcrawler --diff --master /Volumes/RamDisk/xueqiu_2/ --candidate /Volumes/RamDisk/xueqiu_6/ --report /tmp/diff/
动态插件和普通插件, 把插件文件放到工具的plugins目录下可以自动加载.
import com.xueqiu.qa.appcrawler._
//继承Plugin类
class DynamicPlugin extends Plugin{
//重载start方法, 启动时执行
override def start(): Unit ={
log.info("hello from seveniruby")
}
//在每个element的动作执行前进行针对性的处理. 比如跳过
override def beforeElementAction(element: UrlElement): Unit ={
log.info("you can add some logic in here")
log.info(element)
}
//当进入新页面会回调此接口
override def afterUrlRefresh(url:String): Unit ={
log.info(s"url=${getCrawler().currentUrl}")
}
}
技术内幕
截图加红框是如何实现的
使用了java的ImageIO库, 可以对已有的图片进行标记. appcrawler在点击前会先识别元素的位置, 并加上一个红框用于提示.
为什么用很慢的xpath来定位控件
希望是为每个控件赋予一个唯一的标记, 这样后续就可以进行定位分析和各种diff了. 对于大部分没有id和name的控件. 只有xpath能完整表示一个控件
appcrawler用一种虚拟dom来代表实体dom, 具体的类是UrlElement
界面对比技术是怎么实现的
每个控件点击前后的截图和dom结构需要先拿到. PageSource是一种xml结构. (WDA里面是json结构).
需要先把xml和json等结构flatten. 也就是扁平化. 然后对比简单的kv关系即可. 思路借鉴与Twitter的Diffy.

版本计划
跳过了中间的1.6.0版本. 直接对外发布刚开发完成的1.7.0版本
# 1.8.0 [计划]
对子菜单的支持, 智能判断是否有子菜单
支持断点续传机制
支持自动重启appium机制, 用于防止iOS遍历内存占用太大问题
分离插件到独立项目
# 1.7.0
android跳到其他app后自动后退[完成]
截图复用优化提速 [完成]
报告增加点击前后的截图 [完成]
独立的report子命令 [完成]
配置支持动态指令 [完成]
配置不兼容 [重要]
支持自定义报告title [完成]
# 1.6.0 [内测]
增加动态插件 [完成]
支持beforeElementAction的afterElementAction配置 [完成]
修复app的http连接支持 [完成]
支持url白名单 [完成]
支持defineUrl的xpath属性提取 [完成]
未遍历控件用测试用例的cancel状态表示 [完成]
两次back之间的时间间隔设定为不低于4s防止粘连 [完成]
开源计划
- 项目会在十一期间开源, 希望这种设计思路可以传播开造福整个测试行业.
- 不过代码是scala编写请做好心理准备. 我也鼓励用java重新造轮子. 我会在开源的时候公布设计图
商业与开发者计划
为了更好的推进这个工具的发展. 这个产品的发展方向借鉴burpsuite. 但是更开放, 框架主体开源. 靠好用的插件来为企业做商业化服务.
- 插件收费体系. 后面会不断开发更好用的插件做商业服务. 比如用OCR技术做游戏app的自动遍历. 比如遍历的时候接口测试用例自动生成, 自动化的性能分析和代码流diff等
- 服务收费. 可以付费定向为企业提供自动遍历的规则文件编写. 帮助企业更好的遍历自己的app并生成报告.
- 开发者计划. 任何有能力的人都可以编写插件并提交给社区. 社区会协助帮助这些插件进行销售并把钱分成为插件开发者. 类似app store, 开发者可以用python java ruby写插件.
- 收入分成. 收入5%捐赠给社区. 90%返回开发者. 5%分给主框架负责开源的同学.
如果你有志于成为插件的开发者或者公司想快速的实现app的自动遍历. 可以联系我的微信 seveniruby
硬广
我和stuq业余合作了一个小的平民价格(大约初级工程师两天的工资)的培训体系, 讲解移动测试技术的. 主要面向希望在技术方向上有所提升的同学. 欢迎有需求的同学报名.
介绍地址在 https://testerhome.com/topics/5867 收入也会捐给社区5% 快过年了, 攒点路费回家.
,
45 个赞
举报
* 注:本文来自网络投稿,不代表本站立场,如若侵犯版权,请及时知会删除