
测试开发之路 (工具篇)–docker 1.12的swarm mode
本帖已被设为精华帖!,
背景
我一直使用docker管理公司的开发和测试环境。为了提高团队的工作效率。至少人手一整套环境(除了产品各模块外还包含了数据库,etcd等持久化组件)以减少环境冲突。 所以随着业务发展,团队人数增加, 越来越多的环境将服务器资源耗尽。到了一定程度后就会分部门使用不同的服务器以缓解资源的消耗。但到了这时候就有主要了以下两个痛点。
- 没有动态分配资源和负载均衡能力,资源利用极其不合理。会出现某个服务器很忙但是另一个服务器很空闲的情况。
- 部署环境的脚本和镜像在不同服务器上的处理问题。
所以最近工作有空闲的时候开始调研swarm mode,mesos和kubernetes 这种分布式的资源调度框架。今天主要说明一下swarm mode的机制。
docker machine:
docker machine是一个非常有用的学习工具,它能够帮我们迅速搭建起多套装有docker 的宿主机。用以我们试验管理集群。建议大家学会它。下面简单介绍下使用方式。
MAC上安装:
curl -L https://github.com/docker/machine/releases/download/v0.8.2/docker-machine-`uname -s`-`uname -m` >/usr/local/bin/docker-machine && \
chmod +x /usr/local/bin/docker-machine
Virtualbox安装:
如果是在mac上,需要使用一个虚拟机来帮助创建docker host。下载链接:https://www.virtualbox.org/wiki/Downloads
创建docker host:
docker-machine create --driver virtualbox default (manager node 我暂时就命名为default了)
docker-machine create --driver virtualbox slave1
docker-machine create --driver virtualbox slave2
上面我们就很简单的创建了3个带有docker最新版本的宿主机供我们这次demo使用。下面介绍一下简单的命令使用。
- help 查看帮助信息
- active 查看活动的Docker主机
- config 输出连接的配置信息
- create 创建一个Docker主机
- env 显示连接到某个主机需要的环境变量
- inspect 输出主机更新信息
- ip 获取Docker主机地址
- kill 停止某个Docker主机
- ls 列出所有管理的Docker主机
- regenerate-certs 为某个主机重新成功TLS认证信息
- restart 重启Docker主机
- rm 删除Docker主机
- scp 在Docker主机之间复制文件
- ssh SSH到主机上执行命令
- start 启动一个主机
- status 查看一个主机状态
- stop 停止一个主机
- upgrade 更新主机Docker版本为最新
- url 获取主机的URL
- ssh 进入到宿主机中
例如我运行docker-machine ssh default这条命令。我们就会以ssh的方式进入到manager这台主机中。
swarm mode
swarm mode是即swarm和swarmkit之后,内置在docker1.12极其以上版本的集群管理框架。特点是简单,易用,易理解。相较于mesos和kubernetes,它的简单易用很适合在公司内搭建非生产环境集群,尤其是给运维经验不足的QA使用。普通的docker使用者可以很快的过渡到swarm mode的使用方式上。当然业界现在基本没人使用它搭建生产环境,尤其是其overlay的网络性能尤其让人诟病。
搭建一个集群
用上面docker-machine准备的三台机器我们来搭建一个集群
初始化manager node:
docker swarm init --listen-addr 192.168.99.100:2377 --advertise-addr 192.168.99.100
如果机器有多个ip地址要指定–adverties-addr选择一个ip,否则会报下面的错:
Error response from daemon: could not choose an IP address to advertise since this system has multiple addresses on different interfaces (10.0.2.15 on eth0 and 192.168.99.100 on eth1) - specify one with --advertise-addr
命令成功后会返回一个全球唯一的token。这是初始化命令到docker hub上申请的token。用来唯一标识swarm的manager。 之后node加入到集群的时候会用到。这样我们就将
将worker node 加入到集群中
docker swarm join \
--token SWMTKN-1-47e8gcgrv91taf01zdr252wp7no10m3nb9tgjcgyjgy9r1fszp-7y7h5c06f6qul2t6hwml0d1c7 \
192.168.99.100:2377
在这里使用之前初始化manager的时候生成的全球唯一的token。
发布一个服务
在这里需要注意的是在swarm mode中对外暴露的是服务(service)的概念,而不是容器。在swarm mode的设计中,为了保持高可用架构,它准许同时启动多个容器共同支撑一个服务,如果一个容器挂了,它会自动使用另一个容器。所以这里单机的docker engine不同。大家要适应这个概念。当然我们在测试和开发环境中基本上不用着什么高可用,我们知道有这么个东西就行了。
docker service create --replicas 3 --mount "type=bind,source=$PWD,target=/var/lib/registry" --publish 8080:80 --name helloworld alpine ping docker.com
在manager节点上运行上面这条命令就使用alpine这个镜像创建了名为helloworld的服务。–replicas 3 这个参数代表给这个服务启动3个容器(刚才说的高可用) ,–mount 这个参数其实就是docker engine的-v,将数据卷挂载到宿主机。 –publish就是docker engine的port,将容器的80端口map到集群的8080端口中。(注意:不论你访问集群中哪一个node的ip地址。只要访问这个端口号。 swarm node都会路由到正确的容器中)
下面我们运行docker service ls这条命令来查看一下我们所有的服务


可以看到我们刚才创建的helloworld上的3个实例都已经启动了。我们再运行一个docker service ps helloworld来查看一下部署的详细情况

可以看到swarm根据内置的资源分配策略,选择了在slave1上部署了两个容器,在manager node上部署了一个容器。
其他命令和参数
swarm mode还可以让我们控制更多东西,例如跟docker engine的-e一样可以控制环境变量的-env。可以限制容器资源使用的–reserve系列参数等等。大家可以使用–help或者去官方文档中查看。一切都跟docker engine很像,我就不多说了。
容器夸主机互联方案
我们都知道在宿主机中,docker会创建一个默认的docker0网桥用以桥接宿主机和容器。 这个docker0网桥对于宿主机来说是一个虚拟的网络设备。但是对于docker 容器来说就是一个三层交换机。所以我们的容器可以通过docker0访问外网(三层交换机有路由功能)。但是外部无法访问容器,因为每台宿主机上的docker容器都分别在自己的一个私有的局域网络中,也就是说外部路由器没有这些容器的路由。所以我们在没有集群的时候一般选择briage方案将docker容器与宿主机部署再同一个网络下,或者直接以map容器端口到宿主机端口上,或者直接以host网络模式启动容器来达到外部访问容器服务的目的。 这几种方案我不详细讲了,之后转们开一个帖子说docker的网络方案。今天我们讲一下swarm node内置的overlay网络。
overlay
简单介绍下overlay,我们学过计算机网络基础。都知道有一句常说的话是2层(数据链路层)转发,3层(网络层)路由。 2层设备(网桥,2层交换机)并不记录逻辑地址(ip地址),而是记录物理地址(mac) 通过广播的形式寻址。 而三层设备(三层交换机,路由器)通过路由规则解析逻辑地址并一跳跟着一跳的通往目的主机。 他们都属于底层的网络通信协议。同一台宿主机的同一个网桥下的所有容器可以互相访问,因为他们处于同一个物理网络,走2层协议用mac地址进行通信。 容器可以访问外网,因为默认的docker0相当于一个三层交换机,具有三层网络的路由功能。上面说的使用briage模式达到外部通过ip地址访问容器的方式利用的就是三层网络的通信协议。而overlay处于应用层,是上层的网络通信协议。通常需要借助一些K,V存储设备来保存信息,例如etcd,ZK等等,它的性能比较慢,在网上看的资料说docker的overlay 网络方案有30%的性能折损。这也是swarm mode不适合生产环境的原因之一。具体的原理我也没深研究过,就不卖弄了,大家有兴趣的自己去网上查一下资料吧。
创建overlay的网络设备
swarm mode 内部已经支持了overlay的网络,所以不需要我们增加额外的K,V机制去配置overlay的网络。 你需要确保以下的端口已经被打开
- Port 7946 TCP/UDP for container network discovery.
- Port 4789 UDP for the container overlay network.
运行命令:
docker network create \
--driver overlay \--subnet 10.0.9.0/24 \--opt encrypted \
my-network
这时候我们就创建了一个overlay的网络。然后我们在创建服务的时候使用–network 参数指定使用这个overlay网络。那么不论容器处于集群中的哪个节点。他们都可以正常的互相通信。
service discovery
好了现在我们的容器可以互相访问了,但是我们怎么知道目的主机的ip地址呢? 答案是不知道,因为每次启动容器都是又overlay动态的分配一个VIP(虚拟IP地址)。只有在容器创建之后你才知道IP地址是什么。那么在制作镜像的时候你怎么知道使用哪个ip地址才能访问到我们真正想要去的容器呢? 熟悉docker engine的人一定知道link这个参数。 swarm mode的service discovery同样实现了类似的功能。swarm会将容器的VIP map到swarm的内置的dns中,使用service name作为域名。所以集群的容器可以使用服务名称当做IP地址来互相访问。
高可用
接下来我们讲讲swarm mode的一致性策略,也是swarm mode的高可用机制,作为QA的话这个其实不用了解,因为测试环境一般没有那么大的规模需要做高可用,对此有兴趣的同学可以看一看。先讲讲高可用的概念,我们的例子里只有一个manager node控制所有的worker node,这个唯一的节点维护着所有的服务,健康检查,service api。一旦manager节点挂掉我们的服务就会瘫痪。所以需要运行多个manager 节点来保持我们的高可用。但是多个manager 节点会碰到另一个问题就是信息的一致性问题,如果当前的leader的manager节点挂了,那么上面的信息怎么办?我们知道早期的swarm 以及其他的一些分布式框架都是用etcd或者ZK这种K,V存储辅以一致性算法来保证master节点(在swarm mode中叫manager节点)的高可用的。swarm mode虽然不使用etcd或者ZK这些东西(可能是已内置了),但是它依然是使用Raft一致性算法的。这里简单介绍一下Raft 一致性算法的概念:
Raft 一致性算法概念描述
在一个由 Raft 协议组织的集群中有三类角色:
- Leader(领袖)
- Follower(群众)
- Candidate(候选人)
就像一个民主社会,领袖由民众投票选出。刚开始没有领袖,所有集群中的参与者都是群众,那么首先开启一轮大选,在大选期间所有群众都能参与竞选,这时所有群众的角色就变成了候选人,民主投票选出领袖后就开始了这届领袖的任期,然后选举结束,所有除领袖的候选人又变回群众角色服从领袖领导。这里提到一个概念「任期」,用术语 Term 表达。关于 Raft 协议的核心概念和术语就这么多而且和现实民主制度非常匹配,所以很容易理解。三类角色的变迁图如下,结合后面的选举过程来看很容易理解。

Leader 选举过程
在极简的思维下,一个最小的 Raft 民主集群需要三个参与者(如下图:A、B、C),这样才可能投出多数票。初始状态 ABC 都是 Follower,然后发起选举这时有三种可能情形发生。下图中前二种都能选出 Leader,第三种则表明本轮投票无效(Split Votes),每方都投给了自己,结果没有任何一方获得多数票。之后每个参与方随机休息一阵(Election Timeout)重新发起投票直到一方获得多数票。这里的关键就是随机 timeout,最先从 timeout 中恢复发起投票的一方向还在 timeout 中的另外两方请求投票,这时它们就只能投给对方了,很快达成一致。
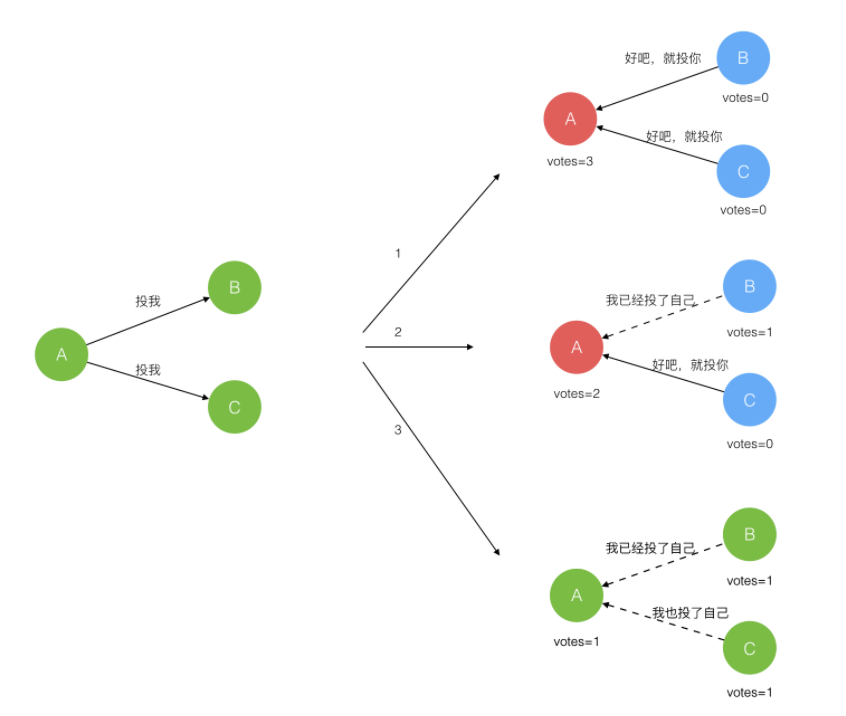
选出 Leader 后,Leader 通过定期向所有 Follower 发送心跳信息维持其统治。若 Follower 一段时间未收到 Leader 的心跳则认为 Leader 可能已经挂了再次发起选主过程。
Leader 节点对一致性的影响
Raft 协议强依赖 Leader 节点的可用性来确保集群数据的一致性。数据的流向只能从 Leader 节点向 Follower 节点转移。当 Client 向集群 Leader 节点提交数据后,Leader 节点接收到的数据处于未提交状态(Uncommitted),接着 Leader 节点会并发向所有 Follower 节点复制数据并等待接收响应,确保至少集群中超过半数节点已接收到数据后再向 Client 确认数据已接收。一旦向 Client 发出数据接收 Ack 响应后,表明此时数据状态进入已提交(Committed),Leader 节点再向 Follower 节点发通知告知该数据状态已提交。

在这个过程中,主节点可能在任意阶段挂掉。我们通过在这些节点中复制信息的方式防止数据信息丢失,其中的细节在这不描述了。有兴趣的在家网上查一下资料吧。我的图也是网上剽窃下来的哈哈。
swarm mode中的manager node和worker node
下面是swarm node的架构图:

manager node:
在swarm mode中,所有节点分为manager node和worker node。 manager node作为整个集群的调度者,负责分配资源,分发task,管理各种service。 同时manager node使用一种Raft 一致性算法来保持集群的高可用状态。 这种算法是在所有的manager node中采取选举方式,决定哪一个ndoe是leader。 所以为了保持高可用和容错率,需要保持多个manager node。通过上面的Raft一致性算法的描述我们知道,这种算法在决定leader的时候是通过选举的方式,所以为了保持这种机制的有效性,必须维持至少3个以上的容器才能保持有效的容错率和高可用。 下面是官网的信息:
- A three-manager swarm tolerates a maximum loss of one manager.(3个manager node 可以有一个的容错率)
- A five-manager swarm tolerates a maximum simultaneous loss of two manager nodes.(5个manager node 可以有2个的容错率)
- An N manager cluster will tolerate the loss of at most (N-1)/2 managers.(N个manager node 可以有(N-1)/2个的容错率)
Docker recommends a maximum of seven manager nodes for a swarm.(推荐在一个集群中保持7个manager node)
同时一个manager ndoe也是一个worker node,也就是说manager node也可以执行task,启动容器。 但是我们可以配置manager节点为manager only模式。上面说推荐在一个集群中保持7个manager node。既然manager node也可以同时是worker node,那为什么不让所有的节点都是manager呢? 因为manager node为了保持一致性会有很多额外的资源开销。
worker node:
worker node就是实际执行任务的节点。 它不负责维护集群的整体信息,也不负责维护集群的API。这个就没啥好说的了。
为集群加入manager node
加入manager node的方式也很简单,我们上面init 一个swarm 集群的时候会返回一个token,那个token是worker 节点加入集群的token,现在我们在manager 节点上运行docker swarm join-token manager这个命令就会得到一个manager node的token。当我们用这个token加入一个集群的时候,就是添加了一个manager node。如下:

总结
接下来会去调研一下mesos和kubernetes,然后继续发帖子比较一下他们的不同和优劣。
* 注:本文来自网络投稿,不代表本站立场,如若侵犯版权,请及时知会删除